MAGMA
MAGMA (Matrix Algebra on GPU and Multicore Architectures) is a collection of next generation linear algebra libraries for heterogeneous architectures. MAGMA is designed and implemented by the team that developed LAPACK and ScaLAPACK, incorporating the latest developments in hybrid synchronization- and communication-avoiding algorithms, as well as dynamic runtime systems. Interfaces for the current LAPACK and BLAS standards are supported to allow computational scientists to seamlessly port any linear algebra reliant software components to heterogeneous architectures.
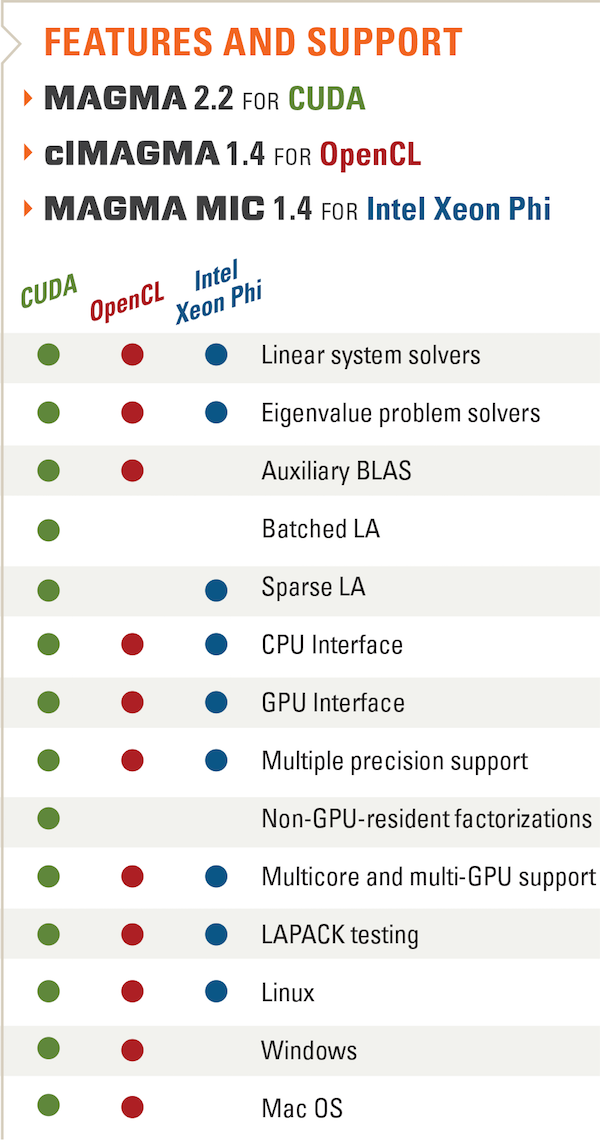
MAGMA allows applications to fully exploit the power of current heterogeneous systems of multi/many-core CPUs and multi-GPUs to deliver the fastest possible time to accurate solution within given energy constraints.
Hybrid Algorithms
MAGMA uses a hybridization methodology where algorithms of interest are split into tasks of varying granularity and their execution scheduled over the available hardware components. Scheduling can be static or dynamic.
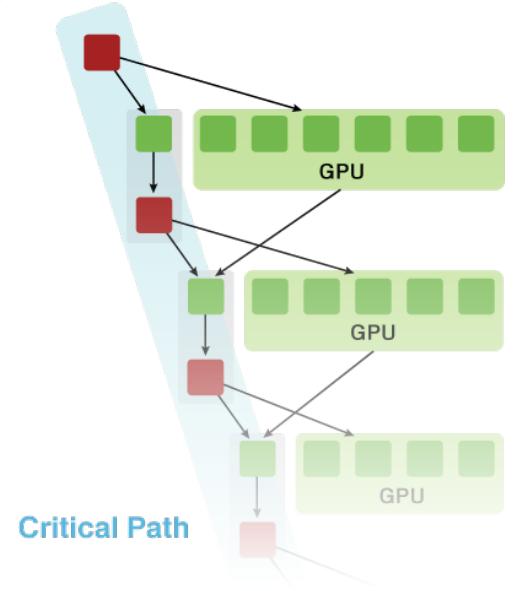
In either case, small non-parallelizable tasks, often on the critical path, are scheduled on the CPU, and larger more parallelizable ones, often Level 3 BLAS are scheduled on accelerators.
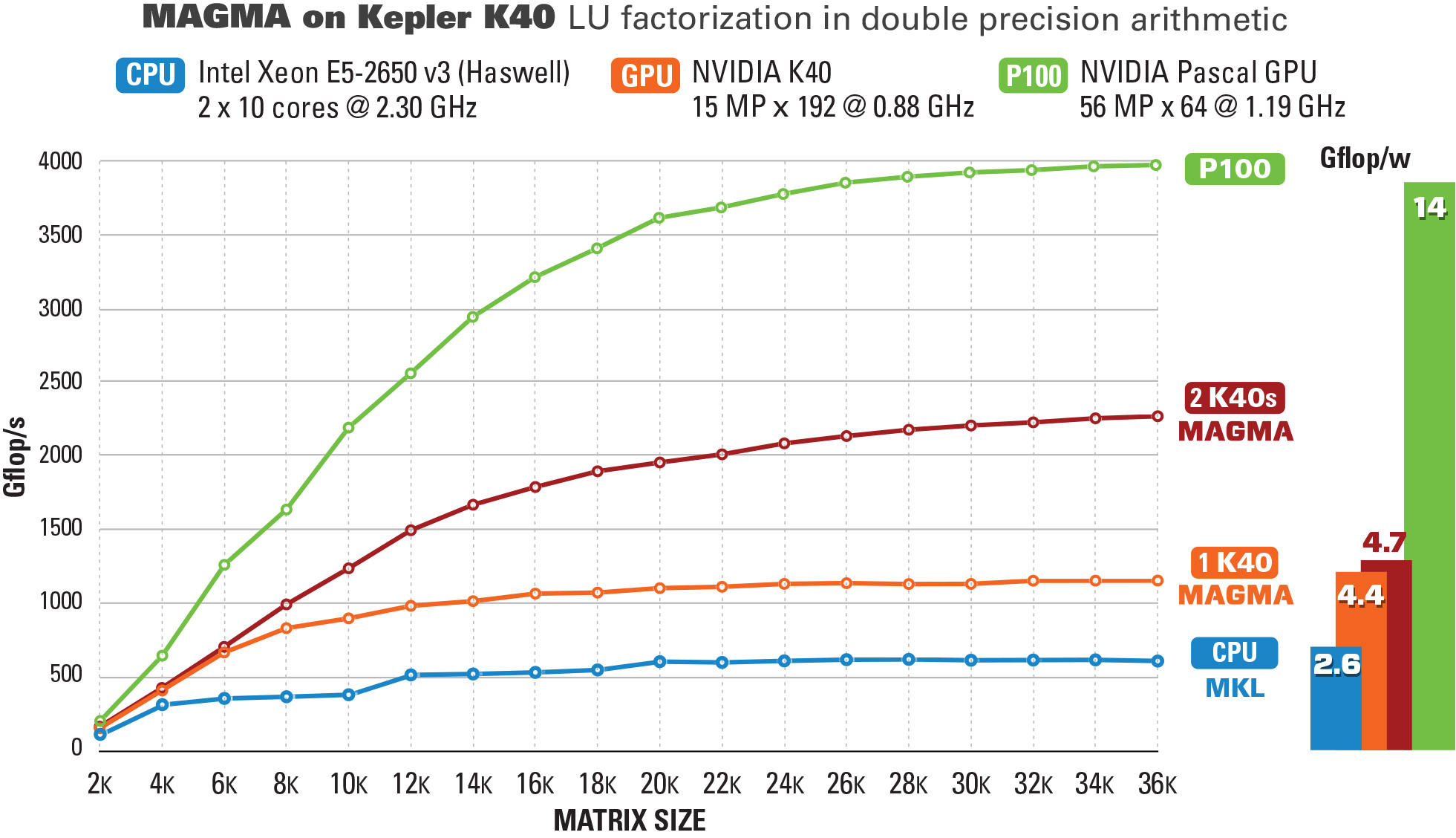
Performance and Energy Efficiency
MAGMA solvers run close to the machine's peak performance. The LU factorization for example, illustrated below, runs as fast as the GPU can run matrix-matrix multiplications (GEMM), as the small tasks on the critical path are offloaded to the CPU and overlapped with the GEMMs on the GPU.
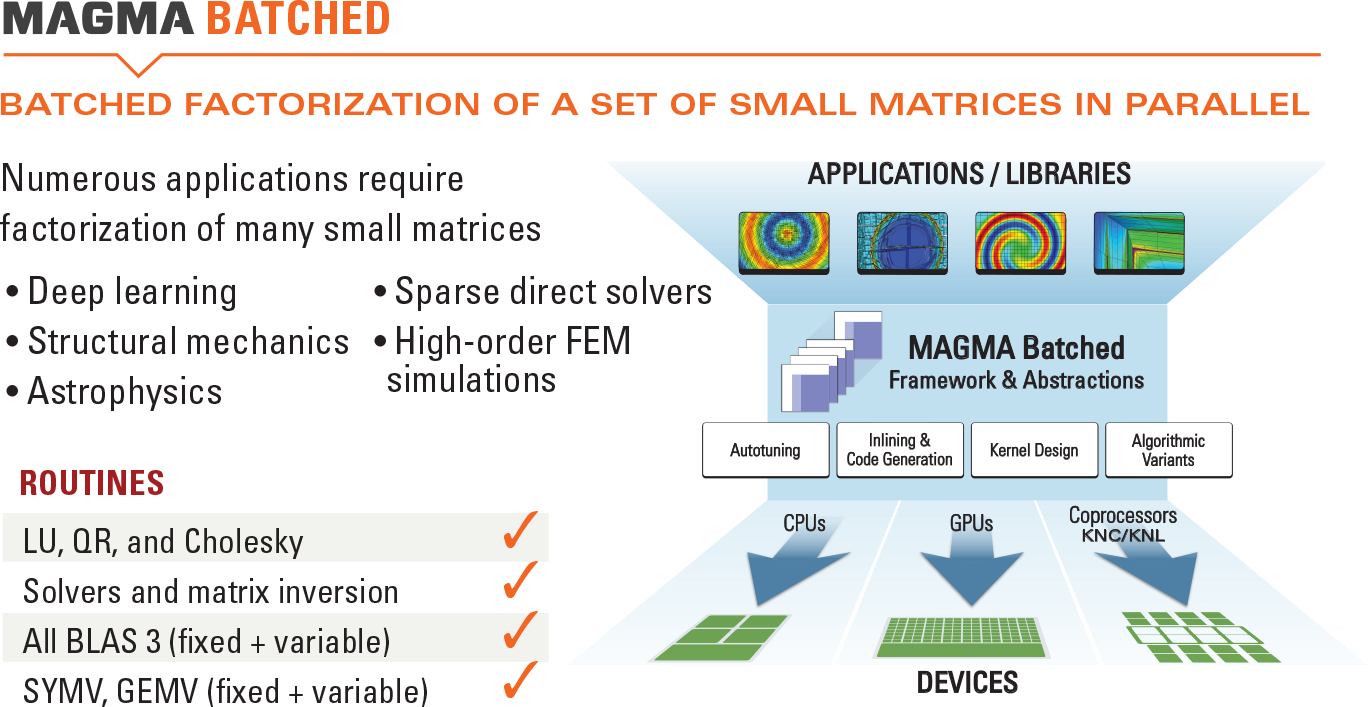
MAGMA Batched
MAGMA Batched targets small linear algebra operations. Small computational tasks are difficult to parallelize, but applications usually require the computation of many small problems, which can be grouped together (batched) and executed very efficiently. MAGMA Batched is being extended now under the CEED project to support tensor data structures and tensor contractions for high-order methods.
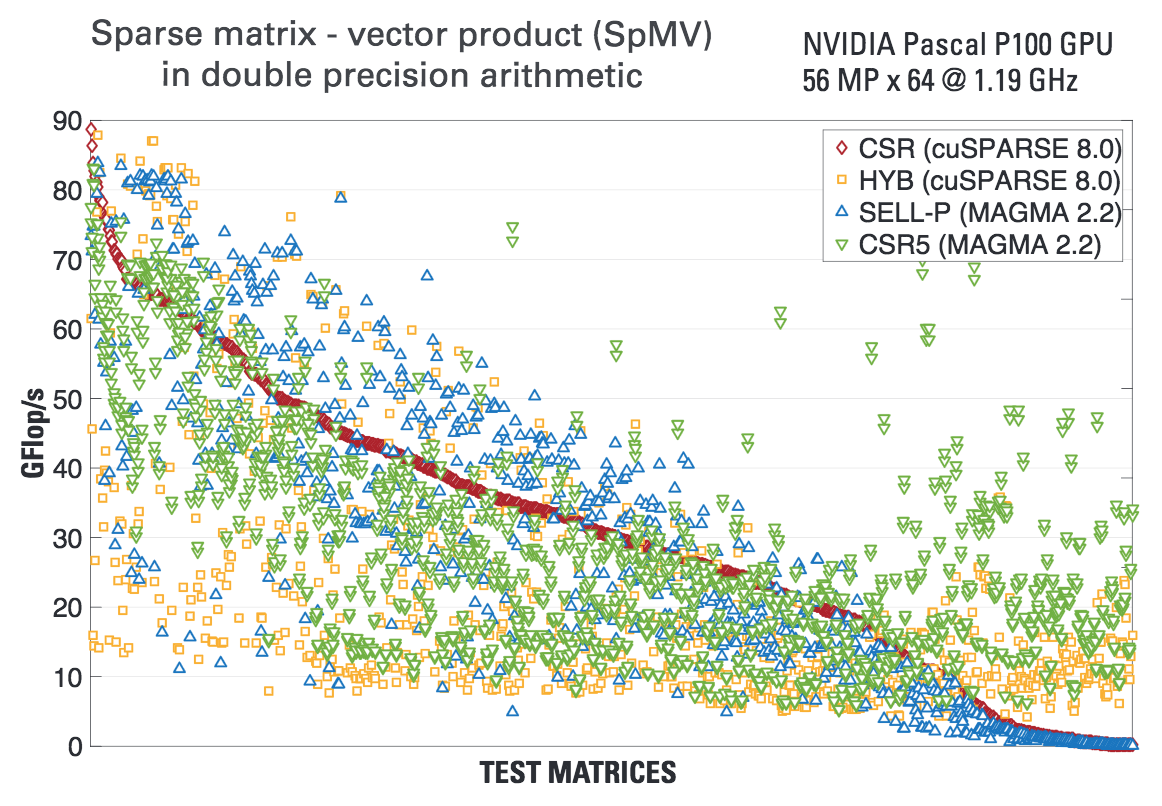
MAGMA Sparse
MAGMA Sparse targets the development of high-performance sparse linear algebra operations on accelerators - from low-level kernels like SpMVs and SpMM, to higher-level Krylov subspace iterative solvers, eigensolvers, and preconditioners.
MAGMA Development
MAGMA is being developed at the Innovative Computing Laboratory of the University of Tennessee.
In CEED, MAGMA is primarily involved in the efforts of the Software, Hardware and Finite Element thrusts.
For more information, see the MAGMA website: http://icl.cs.utk.edu/magma.